Mako’s Doxygen Documentation
The Mako SDK has quite a large surface area, all diligently commented by our engineers to produce Doxygen documentation. Having all this high-quality documentation at our customers’ fingertips is one of the strong benefits of our SDK.
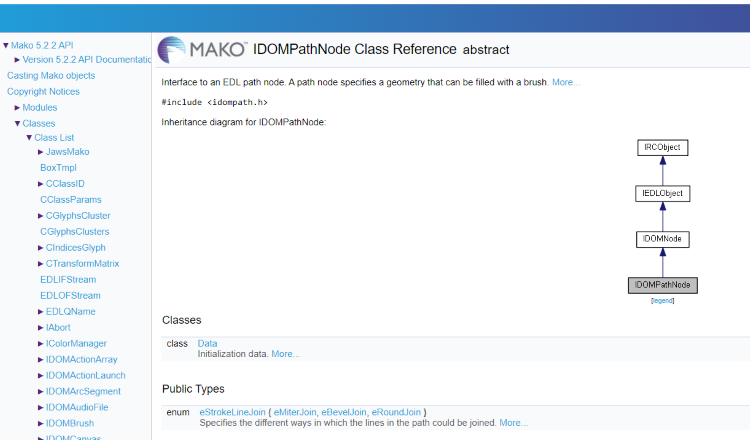
Our Doxygen documentation.
This all sounds great, but some feedback that we hear is that although the documentation is good, it’s let down by the ability to search and find it. Indeed, Doxygen’s standard search mechanism is not very good. Specifically, the standard search will simply try to match the start of an indexed symbol. No use then for looking for concepts rather than types.
There’s some options that Doxygen provide to improve the experience, but we thought we’d look at this as an opportunity to see how we could do better more generally.
If you’re a Mako customer, you’ll be aware that we’re currently moving our documentation over to a new Confluence site. Since Confluence has good search capabilities, it got me wondering if we could upload the Doxygen output to Confluence.
From some googling, it seems that Doxygen has a couple of output types, and Confluence has a few import formats, but unfortunately no intersection. Neither does it seem that there are any tools that do the job too.
Enter the Shed and a coding project!
Writing a Doxygen to Confluence Tool
So the plan is to write a command line application which will convert and upload our Doxygen output to Confluence. Specifically, we’ll look at the following path:
Doxygen > XML output > Doxygen-To-Confluence tool > XHTML Storage Format > Confluence
So there’ll be two main parts the tool will need to tackle:
- Convert the Doxygen XML output to XHTML Storage format.
- Upload the XHTML using Confluence REST APIs to build the documentation.
Since I’m comfortable with C# and .NET Core, I’ll write this as a simple .NET Core command line app.
Conversion from XML to XHTML
The first job is to run the Doxygen tool over our Mako source code, but instead of outputting HTML, we output XML instead. This creates a folder full of XML, containing the information in all the comments, but without the presentation details.
From here, we use some C# to parse through the XML and combine it with the XHTML templates, to produce a series of XHTML storage format Confluence pages.
This part isn’t particularly hard, but a little time consuming since the Doxygen schema is a little large.
So much so that we take the approach of picking off small parts at a time until we support enough of the schema to be useful.
Uploading to Confluence
This is the relatively easy part. After reading the REST API documentation for Confluence, we find that we need to POST the XHTML page to the following Content URL:
/wiki/rest/api/content
Since it’s an internal tool, we favour the simplicity of using an API token for authentication, along with basic auth.
We had a few small problems initially with 5xx and 4xx errors, which turned out to be issues with properly escaping and URL encoding the XHTML that was sent along with the request.
This was resolved with a little extra code in the form of two extension methods:
And that’s really it.
The Result
So what does the end result actually look like?
Actually, really nice! Here’s some of our documentation in our test instance of Confluence.
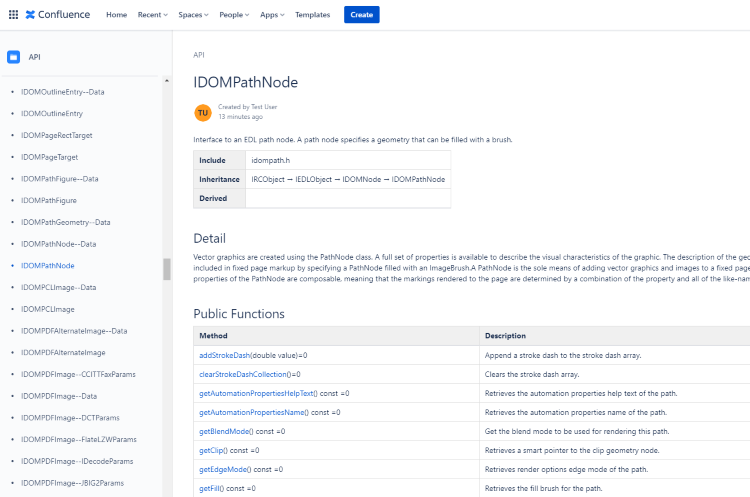
IDOMPathNode documentation in Confluence.