The Idea
As one of the new graduates in the company, we (Alex, Ethan, and myself (Max)) worked on an orientation project as a team. This was a tool to load pdfs and use machine learning techniques to analyze and categorize the pages into one of a predetermined number of types.
The types we decided should be identified were Word documents, PowerPoint presentations, and Excel spreadsheets. If the tool categorized images incorrectly we also wanted to be able to correct and retrain the model to improve overall accuracy.
This project was intended to introduce us to working in a scrum environment as well as help us get to grips with the Mako™ Core SDK, WPF, C# and good development practices. We did this project in particular because all of us thought it would be of interest and possibly useful, and I especially had a specific interest in machine learning and its applications, so I was very enthusiastic!
The Application
The tool is called the Artificial Intelligence PDF Analyzer and Categorizer (AIPAC).
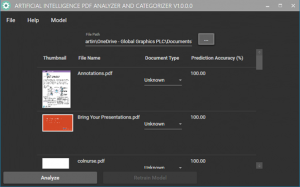
The AIPAC interface
AIPAC is simple to use: you simply select a folder containing one or more pdf files using the browser at the top of the UI and then hit Analyze. The application will then use the Mako SDK to generate an image from the first page in each PDF. Next, a model will then use image classification to predict what label best fits the first page of the pdf and display it in the table along with the prediction accuracy.

An entry in the table after analysis
If this label is known to be incorrect the user can select the correct label from the dropdown menu in the table, and then select Retrain Model. This adds an image of the pdf to the training data of the model, with the correct label, and then rebuilds the model to improve its accuracy in future.
The application also includes the option to export or import models to/from disk, as well as to train an entirely new model based on a new library of training images (in the correct format). These options are all accessed through the Model menu.
Below is a video showcasing the analysis of a folder of pdf files:
Mako
In AIPAC we used Mako SDK to load the pdf files and get thumbnails for them, which were used both in the results table and to be fed into the model for analysis. Alex found it very simple to use, despite going in blind, as there were examples in the documentation covering almost the exact case we wanted.
We found after some initial setup it could basically be left alone and it was easy to get it to do what we needed. In general any trouble we came across was more because of our inexperience and not any issues within the SDK itself! For the most part it was as simple as setting up a Mako Singleton class in our solution, which could be called whenever and wherever we needed it:
Rendering is then as straightforward as the documentation suggests.
Machine Learning
My main focus for a large portion of the project was the machine learning side of things, because I already had a keen interest and some understanding of how it might work! This included an investigation into different frameworks that we could use. Coming from a Python background I did not have much of a grounding in machine learning tools for C#, so that was an interesting area to research.
Underneath the bonnet AIPAC uses Microsoft.ML, a C#-based Tensorflow distribution created and maintained by Microsoft as part of ML.Net. We chose this framework partly because it allows for transfer learning of models, where a model that is already trained to do a specific task, for example image classification, can be loaded and then optimized to the details of the task at hand.
Transfer learning allows for the training of a model with a relatively small training dataset, using tens of labelled examples rather than hundreds or thousands. Additionally, the Microsoft.ML framework is very well documented, has extensive code examples on GitHub which I found to be invaluable for the project, and can be set up to use a GPU which can speed up processing substantially (although this feature is not used for this project).
Microsoft.ML classification models work by using a set of prelabelled training data to train the model, which can then be saved to a zip file and reloaded for use. Once loaded the model can be given a new piece of data and will return an array of scores based on the predicted probability of the data matching each of the labels the model is able to recognize. In the case of the image classifier each image is loaded as a byte array and must be stored in memory for the duration of the training and prediction phase. Each array is stored in a class along with the associated label, which in this case was taken from the name of the folder in which the image was stored. The training set is then shuffled and split into training and testing sets before being loaded into the memory, which is handled by the code below:
This results in the image data being in a format which can be processed by the neural network, allowing this dataset to be fed into the model to train and then the model saved using the code below:
In this code the data is split into training and testing sets using the method, with an 80:20 split ratio. The pipeline for the model is then set up, taking the ImageClassification trainer which loads the pretrained neural network and giving it pointers to where the labels for the data are stored. The column for the predicted label is then appended to the dataset ready for prediction. After the pipeline is built the model is fitted to the training data, which produces the model. The model can be used within the program from the variable, but in this case is saved to disk as a zip file for later use.
After the model has been saved it can be loaded and used to predict the label of a new image. This is done by creating a PredictionEngine, which takes the loaded model and uses it to make a new instance of a specified type, ours contains the predicted label and the confidence of the prediction:
This information is then returned to the UI and updated in the results table. We used multi-threading to shorten the analysis time with larger sets of pdfs by analyzing multiple pdfs at once. Whilst this did speed up analysis I discovered that on particularly large sets (~100 files) it could cause some quite horrendous slowdown if left unlimited, so in the end I set the maximum number of threads to 5 to avoid this.
Conclusions
AIPAC was an enjoyable and challenging project and resulted in an interesting tool which could feasibly be built on to produce an application with a lot of utility, allowing automatic categorization of a large set of pdf files by type. Potentially knowing the type of document may allow a workflow to tune how it’s processed or RIPed further down the line, for improved quality or performance.
The Microsoft.ML framework was surprisingly easy to work with, if a little convoluted at times, but the large amount of documentation meant all the information was out there, it was just a matter of finding it. We also gained a lot of invaluable knowledge about WPF, Mako, and multi-threading, and in particular the difficulties that threads can cause when unit testing!