Searching in PDF documents has never been an easy, or pleasurable task. From a user’s point of view, it seems like it should be trivial to implement. All the text is there on the page, why can’t it find what I’m searching for?
Sometimes when you need to find something in a document, it might not even be mentioned in text. Some documents heavily rely on images, and hey, why not? Images are so much better at conveying a description, over a paragraph of text.
So how can we make these images more accessible to searching? Not to mention, more accessible to those who are visually impaired or use screen readers? The good news is that it’s actually quite easy!
I’ve put together a simple flow, using the Mako SDK. We first iterate through a PDF document, finding all the images inside. Next, we send them off to the Azure Cognitive Services Computer Vision API. The API then returns the description of each image. This description is added to the document in a way that can be searched. In our project, we’ve chosen to add a text note to each image, containing the description.
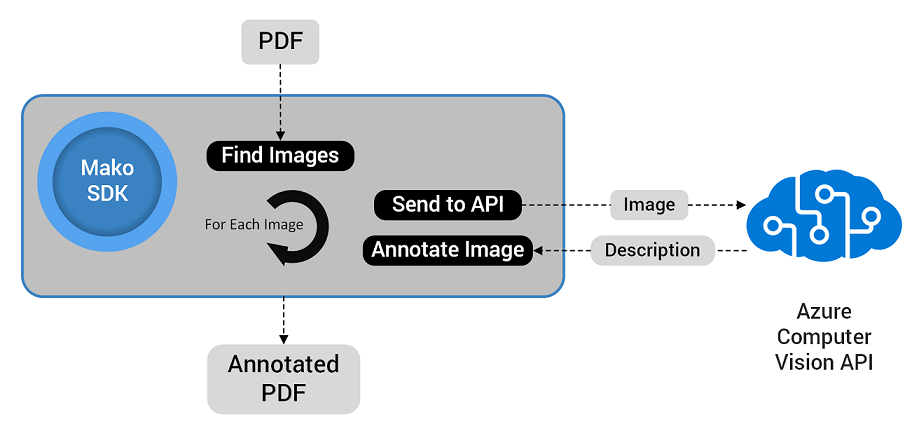
Using the Mako SDK to add descriptions to images.
How does it work?
The first step is to select your document. I’ve taking a couple of pages from the Visit Seattle Official Visitor’s Guide. I’ve chosen these pages, simply because they have some nice images and a pleasing layout.

Our selected document, before processing.
Next, we use the Mako SDK to parse all of it’s images. This is fairly simple with a few lines of C++.
We then send each image to the Computer Vision API. This API then returns the result containing information about the image, including faces, formats, tags and of course, our description.
Once we have a description, we add it to a text note and position it at an appropriate location on the page. Again, hardly any code is required for this. The annotation is added in two stages; first the popup, which contains the description, then the text annotation. The popup is linked to the text annotation.
Finally, once we’ve finished iterating through each image, we write out the updated PDF as a new document. By default, the Mako SDK writes the PDF from scratch, which helps optimize the file size. Of course, if you prefer speed over size, the Mako SDK can also output using the incremental output feature. Using this instructs the Mako SDK to only append the content that was modified or added.
And after all of that, what does the finished, annotated PDF look like?

The same PDF with descriptive annotations.
Excellent!
You can also download the annotated version of the PDF here. You’ll probably notice that some of the descriptions aren’t quite right. For example, the picture of the bridge in the top left hand corner is annotated as ‘a train crossing a bridge over the river’. It’s close though; it is a bridge, and we could assume it’s a river, I’m just not seeing any trains crossing it!
As AI matures, training data sets get larger and technology advances, I can only see this becoming more accurate and more useful, not only in search, but accessibility too.
What else to do?
This flow adds the image description as a text annotation. This is convenient as most PDF viewers will allow searching within comments.
An extension to this could be to add the image description as an Alternative Description. This is part of the Tagged PDF specification in PDF 1.7. Using the image’s alternative description may be preferable, as it’s presence would allow better accessibility for screen readers too.
Interested?
If this has sparked your imagination, or you can think of other exciting uses for our Mako SDK, please get in touch, I’d love to hear about it!

1 Comment
Improving PDF Accessibility with AI and Structure Tagging – Digital Page · April 30, 2018 at 3:08 pm
[…] on from my earlier post about AI and content searching, I’ve been waiting for this release to take it a step further. In my last post, I used AI […]
Comments are closed.